





Something that many of us see is the use of a recursive Common Table Expression (rCTE) to perform "iterative" tasks, something that actually can very likely be performed far quicker with a dataset approach by using a Tally Table. Not as many of us are familiar with a Tally as the rCTE, however, I'll give a brief explanation of both, and then provide some speed tests to show by just how much a Tally can out perform an rCTE. TL;DR: Conclusion.
All these tests were performed on my Home Workstation.
The recursive Common Table Expression (rCTE)
The name effectively gives this away, but an rCTE is literally what it says on the tin; it's a Common Table Expression that will recurse through the data inside it. This area really powerful (in my opinion) when working with hierarchical data that isn't making use of the hierarchyid datatype, as they allow you to transverse through each layer of the hierarchy. rCTEs utilise a UNION ALL inside it's declaration to reference itself, and so look something like this (with hierarchical data):
WITH rCTE AS(
SELECT YT.ID,
YT.ParentID
1 AS Level
FROM YourTable YT
WHERE YT.ParentID IS NULL
UNION ALL
SELECT YT.ID,
YT.ParentID,
r.Level + 1 AS Level
FROM YourTable YT
JOIN rCTE r ON YT.ParentID = r.ID)
SELECT r.ID,
r.ParentID,
r.Level
FROM rCTe r;Here you can see that in the lower part of the UNION ALL that rCTE is referenced, even though it's inside the rCTE itself.
For the purposes of this article, we're going to be looking at the way you use an rCTE to increment values, rather than transverse a table; and how that performs (poorly) against a Tally. So a Simple rCTe to create the numbers 1 to 100 would look like this:
WITH rCTE AS(
SELECT 1 AS I
UNION ALL
SELECT I + 1
FROM rCTE
WHERE I + 1 <= 100)
SELECT I
FROM rCTe;If you give this a go, you'll see that you get the numbers 1 to 100. The problem with this, as the name suggests, is that it's an iterative task. Each row is processed once in the UNION ALL, and each time it's processed SQL Server adds 1 to the value, till the WHERE causes no rows to be generated.
The Tally Table
The tally looks very different to the rCTE, and the version I use here will work on SQL Server 2008+ (I believe the rCTE was introduced in 2005 or earlier, however, if you're using those old versions you have a bigger problem due to the lack of support). Here we leverage dataset approaches to create a large dataset, and then ROW_NUMBER() to give them all numbers. There are different ways of writing an inline Tally, however, I tend to write them like this (again, generating 100 rows):
WITH N AS(
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS I
FROM N N1, N N2)
SELECT I
FROM Tally;The first CTE (N) is used to create 10 rows, each with a value of NULL. Then then next CTE (Tally) creates Cartesian products with N against itself (yes using the ANSI-89 syntax, but I'd say this is one of the few times ANSI-92 isn't needed). Each time N is Cross Joined with itself, it multiplies the number of rows by 10 (so 6 references to N would create 1,000,000 rows). Then, within the SELECT, I use ROW_NUMBER() to number each row; which are then returned in the final SELECT.
Unlike the rCTE, there's no recursion here, meaning that the rows can all be processed at the same time, not one by one. In other words, this is a set based solution rather than an iterative one.
Speed Tests
Each test was performed at least 5 times and then I use the average time taken to produce the graphs you see. There are some noticeable "bumps" in the graphs, even though I used an average. This is likely due the Host Machine performing other (small) tasks that the containers were running on while the tests were on going; though I tried to keep the number of applications running to a minimum (especially for the latter 2 tests). The first test I'm going to do is with a single incrementing value.
Single incrementing values
This is exactly the same as what I did above, apart from larger data sets. I started with 100 rows, and then incremented by 100 rows until generating 25,000 rows. From perspective of code run, I ran the below to perform the tests; using GO 5 to cause the tests to be run 5 times:
DECLARE @I int = 100;
DECLARE @TestStart datetime2(7),
@TestEnd datetime2(7),
@Rows int;
WHILE @I <= 25000 BEGIN
PRINT CONCAT(N'Testing for ', @I, N' rows.')
SET @TestStart = SYSDATETIME();
WITH rCTE AS(
SELECT 1 AS I
UNION ALL
SELECT I + 1
FROM rCTE
WHERE I + 1 <= @i)
SELECT *
INTO #r
FROM rCTE r
OPTION (MAXRECURSION 0); --As an rCTE is limited to 100 iterations by default
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #r);
DROP TABLE #r;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('rCTE','Incrementing single value',@Rows, @i, @TestStart, @TestEnd);
SET @TestStart = SYSDATETIME();
WITH N AS(
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT TOP (@I) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS I
FROM N N1, N N2, N N3, N N4, N N5, N N6)
SELECT I
INTO #T
FROM Tally;
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #T);
DROP TABLE #T;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('Tally','Incrementing single value',@Rows, @i, @TestStart, @TestEnd);
SET @I = @I + 100;
END;
GO 5All in all, this took about 3 minutes to complete on my Sandbox instance for all 5 tests for each increment of 100 rows. The results quite quickly speak for themselves, where you can see that the time it takes to produce more than 100 rows escalates very quickly for the rCTE. By the time you get to 25,000 rows an rCTE is taking almost a quarter of a second, where as a Tally is still in the single milliseconds:
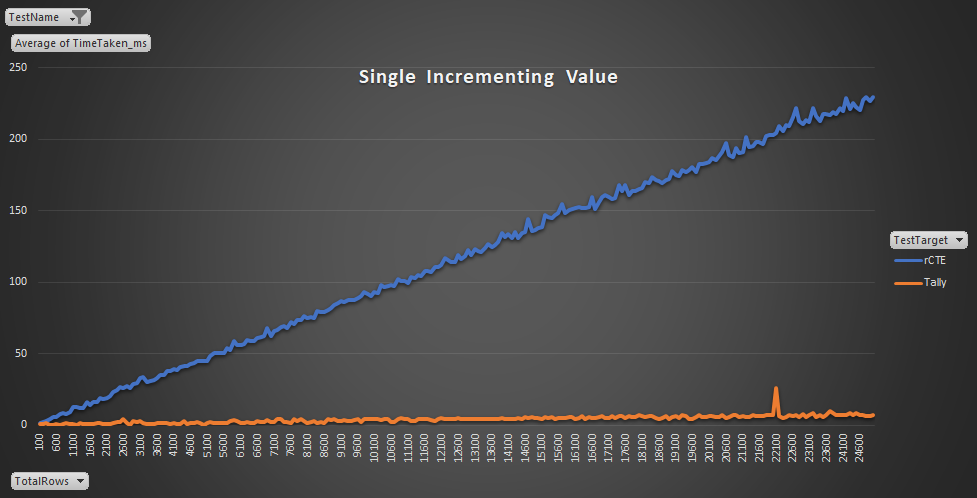
There is a "blip" around the 22,000 mark on the Tally Table. This is due to one of the tests for 22,100 rows taking 94ms to complete, where as the others all took 8-9ms. I should, probably remove this as an anomalous test, however, I have left it in anyway. Most likely this was caused to to a spike in CPU use from the Host Machine.
The longest tests for the tally to complete were on the aforementioned 22,100 rows test (94ms) and another test against 23,700 rows that took 20ms. Other than those 2 anomalous results the Tally always generated all the rows in less than 10ms. For the rCTE, however, the longest period was 265ms, to generate 22,700 rows. Due to the fact that the rCTE takes longer to generate the data, it is therefore more influenced for contention from the CPU. The rCTE also tended to "spike" a single CPU, where as with the Tally it utilised multiple cores/threads to perform the task meaning that it would be less influenced as well if another application (or SQL Server itself) wanted to make use of one of the cores it was processing on.
Multiple incrementing values
This took a different spin on the above. Instead of "counting" to a higher number in each test, I created a table (with an IDENTITY property column) and a Start and End number; 1 and 100 respectively. For each test I then insert 100 additional rows into the (temporary) table and then create rows for each number between the Start and End values. The code I use to perform the tests is below:
DECLARE @I int = 100;
DECLARE @TestStart datetime2(7),
@TestEnd datetime2(7),
@Rows int;
CREATE TABLE #Temp (ID int IDENTITY,StartI int, EndI int);
WHILE @I <= 25000 BEGIN
WITH N AS(
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS I
FROM N N1, N N2)
INSERT INTO #Temp (StartI,EndI)
SELECT 1,100
FROM Tally;
PRINT CONCAT(N'Testing for ', @I, N' rows.')
SET @TestStart = SYSDATETIME();
WITH rCTE AS(
SELECT T.ID,
T.StartI AS I
FROM #Temp T
UNION ALL
SELECT T.ID,
r.I + 1
FROM #Temp T
JOIN rCTE r ON T.ID = r.ID
AND T.EndI >= r.I + 1)
SELECT *
INTO #r
FROM rCTE r
OPTION (MAXRECURSION 0); --As an rCTE is limited to 100 iterations by default
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #r);
DROP TABLE #r;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('rCTE','Incrementing multiple values',@Rows, @i, @TestStart, @TestEnd);
SET @TestStart = SYSDATETIME();
WITH N AS(
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS I
FROM N N1, N N2, N N3, N N4, N N5, N N6)
SELECT T.ID,
Ty.I
INTO #T
FROM #Temp T
JOIN Tally Ty ON T.StartI <= Ty.I
AND T.EndI >= Ty.I;
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #T);
DROP TABLE #T;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('Tally','Incrementing multiple value',@Rows, @i, @TestStart, @TestEnd);
SET @I = @I + 100;
END;
DROP TABLE #Temp;
GO 5This provided similar results to the single value, with the Tally strongly outperforming the rCTE. The test, all in all, took about 3 hours to complete (a lot longer than the prior test), but then at the "top end" was generating significantly more rows (2,500,000 (100 * 100 * 250) rows in the final test). You can see, however, the the Tally never takes more than a second (not even close to in fact) to generate all the rows, where as the rCTE was taking up to 17 seconds to generate all the rows:
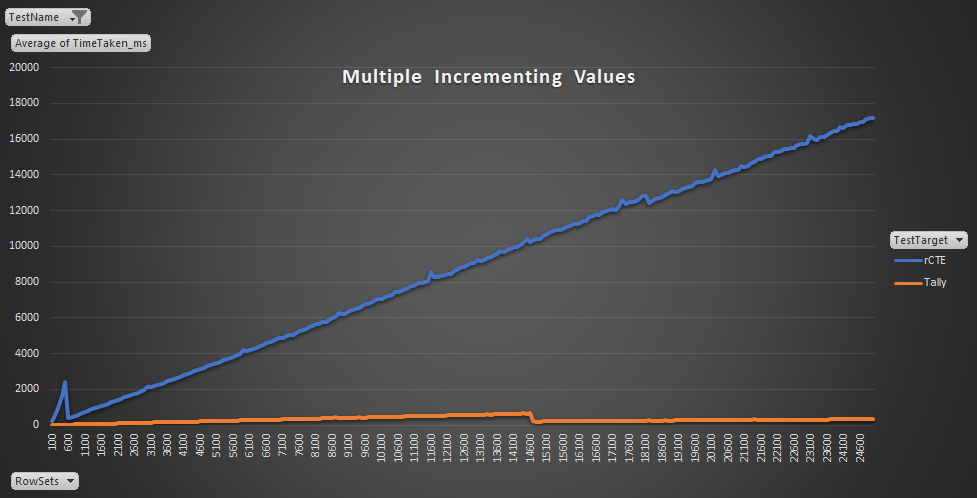
For the rCTE, the longest test took 17,385, when there was 25,000 rows in the table #Temp. All other longest tests (over 17 seconds) where for 24,800 to 25,000 rows. For the Tally, the longest test was actually against 14,400 rows, taking 670ms. In fact, the Tally gradually got slower as it created more rows, and then got faster against at the 14,700 mark. This was consistant in every test, with 14,600 rows taking over 650ms to generate and 14,700 rows taking just over 200ms. Considering that all the tests are completed once, and then performed again, then this due suggest that something in the underlying way the data is created is faster for these larger row amount. I am sure someone more familiar with SQL Server than I might be able to explain why.
The the other hand, the rCTe consistently takes longer to generate each set of rows. Notice, however, that for the first few sets the increase is far more exponential and then it too drops back down. This too was seen across all tests, with 500 Rows taking consistenly over 2,300ms to produce and 600 rows only 400ms. This too seems like the Data Engine was able to make better, or different, uses of resources when there were larger amounts of rows.
Small Intervals
This is similar to the above, however, I randomised the number of rows per group. I also increased the amount of rows generated but also the increment in number of rows tested against in each iteration. This was purely to test if an unknown number of rows that could be generated per group. I used the below code to generate the data:
IF NOT EXISTS (SELECT 1 FROM sys.tables WHERE [name] = N'SmallIntervals')
CREATE TABLE dbo.SmallIntervals (ID int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
StartDate date,
EndDate date);
GO
--Yes I'm using a tally to create the data
WITH N AS (
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT N1.N
FROM N N1, N N2, N N3, N N4, N N5)
INSERT INTO dbo.SmallIntervals (StartDate)
SELECT DATEADD(DAY, ABS(CHECKSUM(NewId())) % 3650, '20100101')
FROM Tally;
GO
UPDATE dbo.SmallIntervals
SET EndDate = DATEADD(DAY, ABS(CHECKSUM(NewId())) % 100,StartDate);And then the below to perform the test:
DECLARE @I int = 1000;
DECLARE @TestStart datetime2(7),
@TestEnd datetime2(7),
@Rows int;
WHILE @I <= 100000 BEGIN
PRINT CONCAT(N'Testing for ', @I, N' rows.')
SET @TestStart = SYSDATETIME();
WITH Data AS (
SELECT SI.ID,
SI.StartDate,
SI.EndDate
FROM dbo.SmallIntervals SI
WHERE SI.ID <=@I),
rCTE AS (
SELECT D.ID,
D.StartDate AS RowDate
FROM Data D
UNION ALL
SELECT D.ID,
DATEADD(DAY, 1, r.RowDate) AS RowDate
FROM Data D
JOIN rCTE r ON D.ID = r.ID
AND DATEADD(DAY, 1, r.RowDate) <= D.EndDate)
SELECT *
INTO #r
FROM rCTE r;
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #r);
DROP TABLE #r;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('rCTE','Small Intervals',@Rows, @i, @TestStart, @TestEnd);
SET @TestStart = SYSDATETIME();
WITH Data AS (
SELECT SI.ID,
SI.StartDate,
SI.EndDate
FROM dbo.SmallIntervals SI
WHERE SI.ID <=@I),
N AS(
SELECT N
FROM (VALUES(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL))N(N)),
Tally AS(
SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) -1 AS I
FROM N N1, N N2, N N3, N N4, N N5, N N6) --1,000,000 Rows, though we're only going to use 100 here.
SELECT D.ID,
D.StartDate,
DATEADD(DAY, T.I, D.StartDate) AS EndDate
INTO #T
FROM Data D
JOIN Tally T ON DATEDIFF(DAY, D.StartDate, D.EndDate) >= T.I
SET @TestEnd = SYSDATETIME();
SET @Rows = (SELECT COUNT(*) FROM #T);
DROP TABLE #T;
INSERT INTO dbo.PerformanceTest (TestTarget,
TestName,
TotalRows,
RowSets,
TimeStart,
TimeEnd)
VALUES('Tally','Small Intervals',@Rows, @i, @TestStart, @TestEnd);
SET @I = @I + 1000;
END;
GO 5This took about as long as the prior test, taking some 3 hours for every iteration to finish, however, it also generated a far larger number number of rows. The final test generated 5,045,657 rows, for 100,000 row sets. Throughout the test, the average number of rows per set created was just over 50 (the maximum being 51.45 and the minimum 50.34). A full range was also available in the data, with the smallest gap between StartDate and EndDate being 0 days, and the largest 99 days (which would produce 1 and 100 rows respectively).
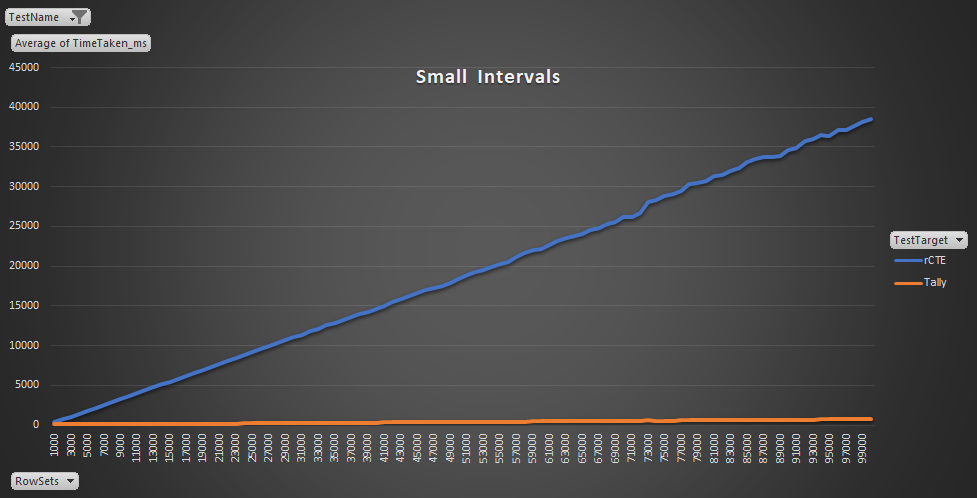
The longest test for the rCTE took 39,294ms (just shy of 40 seconds) to complete and was against the the largest set (100,000 row sets, generating 5,045,657 rows). For the Tally, the longest test was under a second, at 923ms against 97,000 row sets. This is over 200ms longer than the next longest test, which was 757ms against 99,000 and 100,000 row sets. For the final tests, the rCTe was averaging around 50 times slower than a Tally.
Conclusion
It can easily be seen that there is a significant speed difference between using a Tally and rCTE when generating incrementing values. For the test environment I was using, with a 6 core and 12 thread CPU, this is only more obvious. In an environment where you have less cores, this is likely to less obvious, however, with technology that is readily (and more importantly affordably) available it is unlikely you're going to be in an environment where you don't have access to at least 4 cores.
Even if you are in an environment where you had a limited number of cores/threads I still suggest using a Tally rather than an rCTE, due to the fact that when (not if) you move to a new environment with more cores/threads available, your code can immediate make use of the benefit. If you use an rCTE, because you don't see much benefit in your current environment, then when you do move you have the pain of changing all your SQL at a later date to make use of the new hardware. Take the time to write performant SQL now, and then reap the benefit immediately when you upgrade; don't put it off and cause more work in the future.
An environment you may not see a (great) benefit of using a Tally in is when use SQL Server Express, as it's specifically limited to 1 socket or 4 cores (which ever is lesser). I may well perform some tests on an Express Instance limited to 2 cores at a later date, to see how much of a difference this makes.
For those interested, you can also find the raw data from the tests (and some extra tests) here.
Great article
the link to the raw data is not found
Should work now, Kamel. Thanks.